
Photo by Logan Voss on Unsplash
Why Enterprise AI Doesn’t Require Platform Replacement: Four Myths Blocking Your Q2 Roadmap
Three weeks ago, a VP of Engineering told me his CTO had frozen all AI pilots until the company decided whether to “go all-in on Anthropic or stick with Microsoft.” The logic: you can’t build enterprise AI capabilities on top of legacy SaaS infrastructure. You need a new foundation. The team had spent nine weeks debating vendors instead of shipping a single feature. According to Forrester’s 2025 Enterprise AI Adoption Report, 62% of AI initiatives stall in vendor selection, and most never restart. The assumption driving this paralysis — that AI transformation requires platform replacement — is the most expensive myth in enterprise software right now.
David Ohnstad has watched this pattern repeat across multiple organizations in the past six months. The InformationWeek piece on Anthropic reordering SaaS isn’t wrong about the disruption, but it’s being misread. Executive teams are interpreting “reordering” as “replacement” and treating Q2 budget decisions as binary choices: rip out your current platforms or fall behind. The reality is more nuanced and far less dramatic. Most successful AI integrations in enterprise software don’t replace existing systems. They layer on top through APIs, orchestration middleware, and selective augmentation. The companies moving fastest aren’t the ones making the biggest platform bets. They’re the ones who understand that AI capabilities and SaaS infrastructure are orthogonal concerns.
This confusion is burning executive credibility, stalling pilots that should have shipped weeks ago, and creating a false choice between moving fast and betting the farm. The myth persists because vendor messaging conflates capability with infrastructure, and because the loudest voices in the space have a commercial interest in convincing you that transformation requires replacement. Let’s dismantle four specific beliefs that are blocking H2 roadmaps and costing companies months of progress they won’t recover.
Myth One: AI Capabilities Require AI-Native Platforms
The belief: if you want to deploy AI agents, generative search, or predictive analytics, you need to migrate to a platform that was “built for AI from the ground up.” This usually means replacing your CRM, your support desk, your analytics stack, or your entire data warehouse with something newer. The pitch is seductive — especially when the vendor shows you a demo where every feature has an AI toggle and the interface feels modern. The implication is that your current systems are fundamentally incompatible with intelligent capabilities.
Why it persists: vendor marketing and architectural ignorance. SaaS vendors with AI-native offerings have every incentive to position older platforms as legacy constraints. But the deeper issue is that most decision-makers don’t understand how AI features actually integrate with enterprise systems. They conflate the intelligence layer with the data layer. If a platform “wasn’t designed for AI,” it must not support AI — the reasoning goes. This ignores twenty years of API-first architecture and the reality that most AI capabilities are delivered through services that sit alongside your existing infrastructure, not inside it.
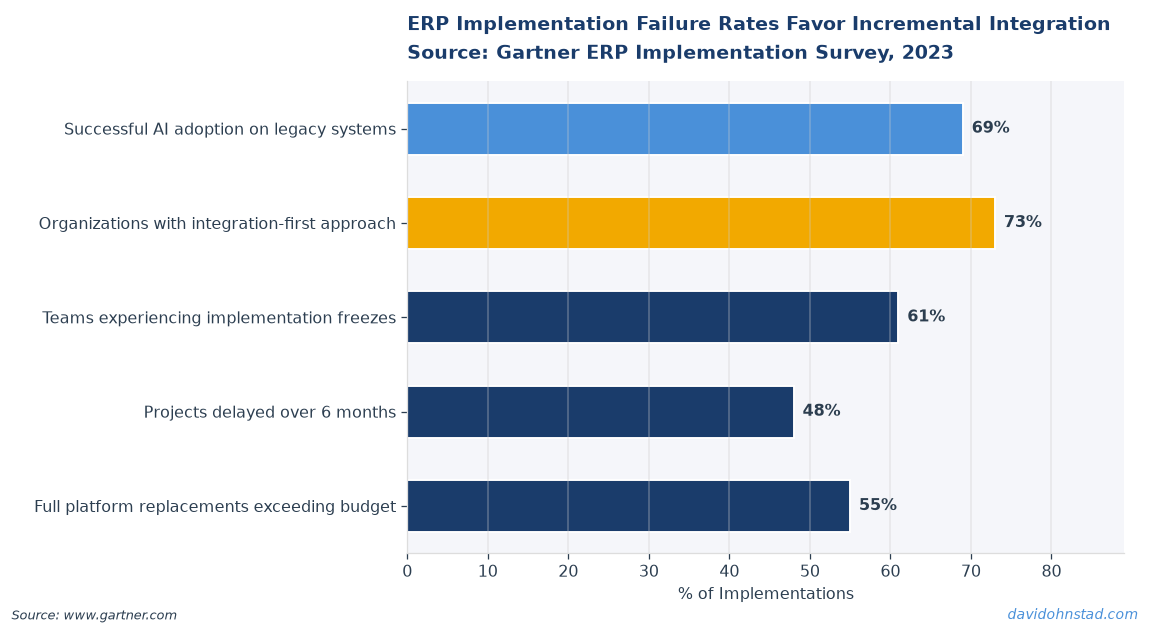
What’s actually true: AI capabilities are delivered through API calls to external models, not through the SaaS platform itself. Your CRM doesn’t need to be “AI-native” to surface AI-generated insights. It needs an integration layer that can call an LLM API, receive structured output, and display it in the UI. That’s middleware, not a platform swap. According to Gartner’s 2024 AI Integration Survey, 73% of enterprises successfully deployed AI features by extending existing platforms through API orchestration rather than replacing them. The companies that moved fastest treated AI as a service layer, not a platform requirement.
David Ohnstad saw this firsthand when a product team at a previous company wanted to add predictive lead scoring to their sales dashboard. The initial proposal was a six-month migration to a “modern AI-powered CRM.” The actual implementation: a two-week sprint to build an API wrapper that called a hosted ML model, returned a score, and wrote it back to a custom field in the existing CRM. Total cost: $8,000 in engineering time and $300/month in model inference costs. The VP of Sales got the feature he wanted without disrupting 200 users or retraining the team on a new platform. The myth that AI requires platform replacement cost the company four months of debate before someone finally asked whether the existing CRM had an API.
The Layered Integration Stack: How Successful Enterprises Actually Deploy AI
Most companies that successfully deploy enterprise AI don’t replace their core systems. They build a layered integration stack that separates intelligence from infrastructure. This is a three-layer model: the data layer (your existing SaaS platforms and databases), the intelligence layer (AI services accessed via API), and the orchestration layer (middleware that connects the two and manages routing, fallback, and logging). Each layer has a distinct job. The data layer stores and retrieves information. The intelligence layer processes requests and returns predictions, generations, or classifications. The orchestration layer handles the workflow between them.
The data layer is whatever you’re already using: Salesforce, ServiceNow, Snowflake, your internal PostgreSQL database. These systems don’t need to change. They need to be accessible via API and structured enough that you can extract meaningful context for the intelligence layer. If your data is a mess, that’s a governance problem, not a platform problem. No amount of AI-native infrastructure will fix schema chaos or missing field definitions. This is where most companies discover that their real blocker isn’t legacy platforms — it’s that nobody documented what “lead_status_code_3” actually means.
The intelligence layer is where the AI lives, and it’s almost always external. OpenAI’s API, Anthropic’s Claude, Google’s Vertex AI, AWS Bedrock — these are services you call, not platforms you migrate to. You send a structured request with context, you get back a response, and you handle it in your application logic. The model doesn’t care what CRM you use. It cares whether you sent it well-formed input and whether your prompt engineering is competent. According to McKinsey’s 2025 State of AI Report, 81% of enterprises using generative AI in production are doing so through third-party APIs rather than self-hosted models. The intelligence layer is rented, not owned.
The orchestration layer is the piece most companies underestimate and where the real engineering work happens. This is the middleware that routes requests to the right AI service, handles retries when an API is rate-limited, logs every call for auditability, implements fallback logic when a model returns garbage, and ensures that responses are written back to the correct system in the correct format. It’s not glamorous. It’s also not optional. Without orchestration, you have a collection of API calls that break unpredictably and nobody can debug. With orchestration, you have a reliable integration that scales and can be monitored like any other production service. This layer is where David Ohnstad spends most of his time when implementing AI features — not debating which LLM to use, but building the boring infrastructure that makes the LLM callable from a business application.
The companies that move fastest treat this as an integration problem, not a transformation project. They pick one high-value use case — lead scoring, contract clause extraction, support ticket routing — and build the orchestration layer to support it. Then they reuse that layer for the next use case. The platform stays the same. The intelligence layer gets called from more places. The orchestration layer grows more sophisticated. No six-month migration. No user retraining. No rip-and-replace risk. Just incremental capability layered onto existing infrastructure.
Myth Two: Successful AI Projects Start with Technology Selection
The belief: the first step in an enterprise AI initiative is choosing the right vendor, model, or platform. Should we go with OpenAI or Anthropic? Do we need a vector database? Is our data warehouse AI-ready? Companies spend months in vendor evaluations, POC bake-offs, and architectural debates before they’ve defined what problem they’re solving or what success looks like. The assumption is that picking the right technology unlocks the capability.
Why it persists: technology is the most concrete part of an ambiguous problem. Executives get nervous when a roadmap says “we’re going to figure out what decisions our sales team actually needs support on” because that sounds like research, not delivery. But they get comfortable when the roadmap says “we’re evaluating Anthropic’s Claude 3.5 versus OpenAI’s GPT-4 for lead qualification.” That sounds like progress. The technology decision becomes a proxy for strategy, and teams convince themselves that once they pick the right vendor, the use cases will reveal themselves. This is backwards, but it’s emotionally safer than admitting you don’t yet know what you’re building.
What’s actually true: successful AI projects start with a decision map, not a technology evaluation. Before you talk to a single vendor, you need to know: what decision does this AI capability support, who makes that decision today, what information do they need that they don’t currently have, and how will we measure whether the AI-generated insight changed the outcome? If you can’t answer those four questions, you’re not ready to pick a model. You’re ready to do stakeholder interviews. According to Harvard Business Review’s 2024 analysis of enterprise AI implementations, projects that began with decision mapping had a 68% deployment success rate. Projects that began with vendor selection had a 31% success rate. The difference is whether you’re building toward a defined need or hoping the technology will create one.
A year ago, David Ohnstad worked with a team that wanted to “add AI to the customer success dashboard.” The initial plan was to evaluate embedding models and build a semantic search feature over support tickets. Three weeks into vendor demos, the Director of Customer Success asked a basic question: what decision would this search feature support that the current keyword search doesn’t? Silence. The team had been so focused on the technical novelty — semantic search is cooler than keyword search — that they hadn’t mapped it to an actual workflow gap. When they finally interviewed customer success managers, the real need surfaced: they wanted to know when a customer’s usage pattern indicated churn risk, not better search. The solution wasn’t a new vector database. It was a weekly batch job that flagged accounts based on login frequency and feature adoption, displayed in the existing dashboard. Total build time: two weeks. The six-week vendor evaluation had been solving the wrong problem.
Myth Three: AI Integration is an Engineering Problem
The belief: if you hire strong engineers and give them access to AI APIs, the integrations will work. This is the “build it and they will come” mindset applied to AI features. The assumption is that the hard part is the technical implementation — calling the API correctly, handling responses, optimizing latency. Once the feature is live, users will adopt it because the capability is obviously valuable. This myth treats AI integration as a purely technical challenge and ignores the organizational, workflow, and trust layers that determine whether anyone actually uses what you built.
Why it persists: engineering is the most measurable part of the process. You can track API response times, error rates, and token costs. You can write tests. You can deploy to production and call it done. The organizational readiness piece — whether users trust the output, whether the feature fits into existing workflows, whether there’s a feedback loop to surface bad results — is harder to measure and often treated as a post-launch concern. Teams convince themselves that adoption will follow deployment. It almost never does. According to Deloitte’s 2025 AI in the Enterprise study, 64% of AI features that pass technical QA are abandoned within six months due to low user trust or workflow misalignment.
What’s actually true: successful AI integration depends less on whether the API call works and more on whether users trust the output enough to act on it, whether the feature fits into their existing workflow without adding friction, and whether there’s a mechanism to surface and fix mistakes. These are organizational design problems, not engineering problems. If your sales team doesn’t trust the AI-generated lead score, they won’t use it — even if the model is 91% accurate. If your support agents have to copy and paste context into a separate tool to get an AI-generated response, they’ll skip it when they’re busy. If there’s no way to flag a bad recommendation and route it back to the team that can retune the model, you’re flying blind on model drift.
David Ohnstad has seen this pattern repeatedly: an AI feature ships, works perfectly from a technical standpoint, and gets zero adoption. The most recent example was an automated contract clause extraction tool built for a legal team. The engineering was solid. The model accurately identified non-standard clauses 87% of the time. But the tool required uploading contracts to a separate interface outside the document management system the legal team already used. Adoption never broke 15%. The feature didn’t fail because the AI was bad. It failed because it added friction to a workflow that was already overloaded. The fix wasn’t better engineering. It was rebuilding the integration so the AI ran in the background when a contract was uploaded to the existing system and surfaced flagged clauses as annotations in the document. Same model. Same accuracy. Different workflow design. Adoption jumped to 73% in two weeks.
This is where the cross-site connection to organizational readiness becomes critical. You can build a technically flawless AI integration, but if the team using it hasn’t been trained on when to trust the output and when to override it, or if leadership hasn’t communicated why the feature exists and what decision it supports, adoption will stall. The companies that succeed treat AI integration as an organizational change initiative that happens to involve engineering, not the other way around.
Myth Four: AI Costs Are Primarily Inference and Compute
The belief: when budgeting for enterprise AI, the big-line items are API costs, compute infrastructure, and model hosting. If you’re using a third-party LLM, you’re paying per token. If you’re fine-tuning or self-hosting, you’re paying for GPUs. These are the costs that show up in vendor quotes and TCO analyses, so teams treat them as the primary cost drivers. The assumption is that if you can afford the inference bill, you can afford the AI initiative.
Why it persists: inference costs are visible, recurring, and easy to forecast. Vendors give you pricing calculators. You can estimate token usage and multiply by cost per token. It feels like rigorous financial planning. The hidden costs — data prep, orchestration engineering, ongoing monitoring, model retraining, compliance and auditability infrastructure — don’t show up on the vendor invoice, so they get deprioritized or ignored entirely. Teams consistently underestimate these costs by 3-5x because they’re harder to quantify upfront and because nobody wants to tell leadership that the real budget is five times the vendor quote.
What’s actually true: for most enterprises, inference costs are 15-30% of total AI spend. The majority goes to data engineering, integration development, monitoring infrastructure, and the ongoing operational cost of maintaining AI systems in production. According to IDC’s 2024 Enterprise AI Cost Analysis, companies that accurately forecasted AI project costs allocated only 22% of total spend to model inference and hosting. The rest: 31% to data preparation and pipeline engineering, 26% to integration and orchestration development, 14% to monitoring and observability tooling, and 7% to compliance and auditability infrastructure. The sticker price is the model. The real cost is everything around it.
David Ohnstad ran into this two quarters ago when a finance team asked for a cost breakdown on an AI-powered forecasting feature. The initial estimate focused entirely on API costs: $1,200/month for model inference based on expected query volume. That number got approved immediately. What didn’t get estimated: the four-week engineering sprint to build the data pipeline that aggregated sales, inventory, and historical trend data into a format the model could consume ($32,000 in engineering cost), the two-week project to add observability so the team could detect when forecasts were drifting ($14,000), and the ongoing operational cost of a data engineer spending four hours a week reviewing flagged anomalies and retraining the model ($8,000/year in labor). Total first-year cost: $67,600. The approved budget: $14,400. The project almost got killed in month two when finance saw the actual spend and accused the team of scope creep. The problem wasn’t scope creep. It was that the initial estimate only counted the line item that showed up on a vendor invoice.
This is where enterprise AI agent costs become a critical planning factor. Teams that treat inference as the primary cost driver consistently underfund the operational and engineering work required to keep AI systems reliable in production. The result: pilots that work beautifully in a demo environment but collapse under real-world data quality issues, scale problems, or compliance audits. The fix isn’t more budget for models. It’s realistic budgeting for the infrastructure, engineering, and operational work that makes models usable in an enterprise context.
What This Means for Your H2 Roadmap
If your organization is debating platform replacement as a prerequisite for AI capabilities, you’re solving the wrong problem. The companies shipping AI features in Q2 aren’t the ones making the biggest infrastructure bets. They’re the ones treating AI as a service layer that integrates with existing systems through APIs and orchestration middleware. They’re starting with decision maps, not vendor evaluations. They’re budgeting for data engineering and monitoring infrastructure, not just inference costs. And they’re treating adoption as an organizational design challenge, not an inevitable consequence of shipping a feature.
For practitioners: stop waiting for permission to replace your platform. Start building the orchestration layer that lets you call AI services from your current systems. Pick one decision that matters, map the workflow, and build the integration. The platform debate is a distraction. For leaders: if your team is three months into vendor selection and hasn’t defined what decision the AI feature will support, reset the process. The vendor doesn’t matter until you know what you’re building. And if your AI budget only accounts for model costs, multiply it by four and plan for the data engineering and operational work that actually determines success.
When was the last time you audited whether your AI roadmap is blocked by a real platform limitation — or by the assumption that transformation requires replacement?
How do you integrate AI capabilities into existing enterprise software without replacing platforms?
Build a layered integration stack with three components: your existing data platforms, an external AI service accessed via API, and orchestration middleware that routes requests and manages responses. Most successful deployments extend current systems through API wrappers rather than migrating to new platforms. This approach reduces risk, preserves user workflows, and delivers capability incrementally without multi-year transformation projects.
What is the biggest hidden cost in enterprise AI implementations?
Data engineering and pipeline development typically represent 30-35% of total AI project costs but are consistently underfunded because they don’t appear on vendor invoices. Teams budget for model inference but underestimate the engineering required to prepare data, build orchestration layers, implement monitoring, and maintain production systems. According to IDC’s 2024 analysis, accurate enterprise AI budgets allocate only 22% to inference and hosting.
Why do most enterprise AI pilots fail to reach production?
AI pilots fail primarily due to organizational readiness gaps, not technical limitations. Users don’t trust model output, features don’t fit existing workflows, or there’s no feedback mechanism to surface and fix mistakes. Harvard Business Review’s 2024 research found that 68% of AI projects starting with decision mapping reached production, compared to just 31% that began with technology selection, highlighting that adoption depends on workflow design and trust.
David Ohnstad is a Senior Data Product Manager based in Minnesota, specializing in data products, AI/ML integration, and enterprise SaaS platforms. Follow his work at github.com/davidohnstad40-netizen. Read more of David Ohnstad’s data product management writing and explore David Ohnstad on leadership and career growth.
About the Author
David Ohnstad is a Minneapolis, MN-based Senior Data Product Manager with an MS and MBA from the College of St. Scholastica. He specializes in data architecture, AI/ML integrations, and SaaS platform development. Outside work, he builds furniture and explores the Minnesota outdoors. Find his work at davidohnstad.com and github.com/davidohnstad40-netizen.