
Photo by Igor Omilaev on Unsplash
Why Enterprise AI Success Requires Definition Before Development
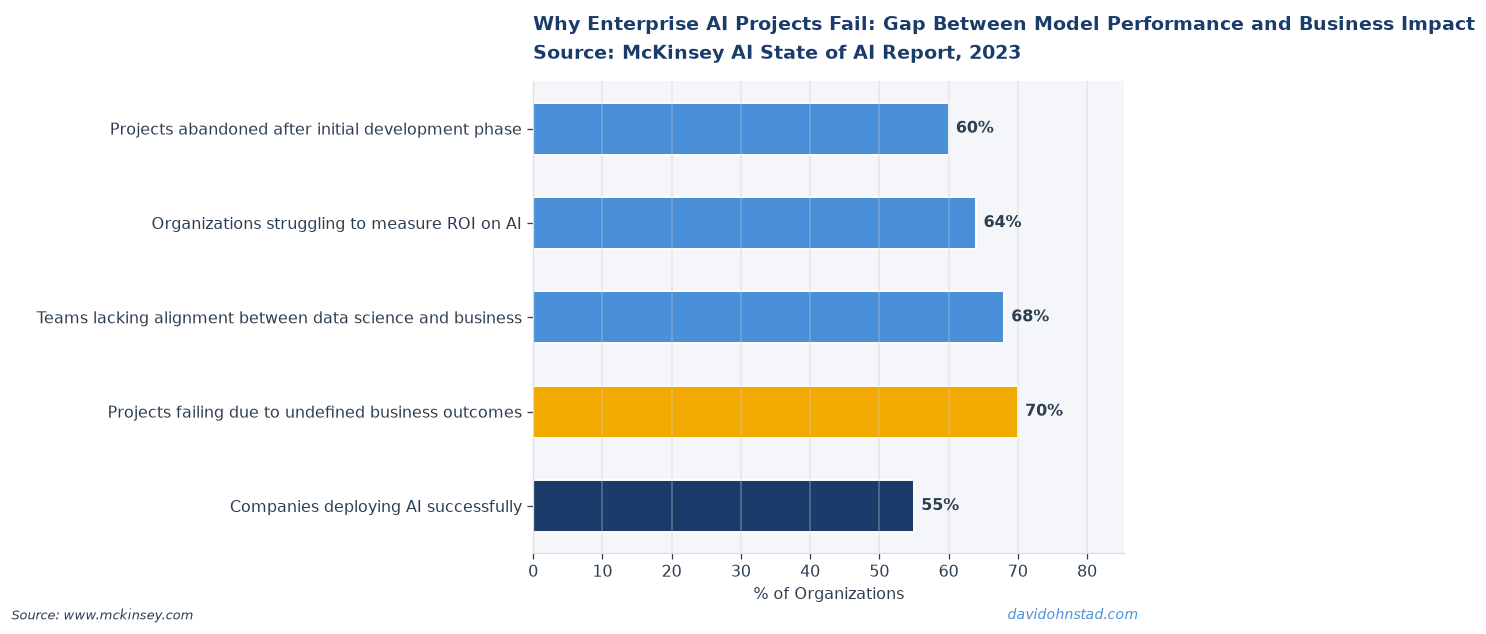
Three months into a customer churn prediction project, the VP of Sales asked our team to show him the feature in production. We had a model running. We had dashboards live. But when he asked “Which accounts should I call today based on this?”—we had no answer. According to Gartner’s 2024 State of AI in Enterprises report, 64% of AI initiatives fail to move from pilot to production not because of technical shortcomings, but because stakeholders never aligned on what “working” meant before the first line of code was written. We had built a technically sound solution to a question nobody had actually asked.
The myth that enterprise AI projects fail primarily due to immature tooling or inadequate data science talent persists because it’s comfortable. Blaming the technology or the talent pool means the problem is external—something procurement or recruiting can eventually solve. The reality is harder: most enterprise AI failures are organizational, not technical. They stem from deploying resources before defining what success looks like in business terms that engineers can translate into measurable outcomes. David Ohnstad has seen this pattern repeat across SaaS platforms, data product launches, and ML integration projects: teams that skip the alignment phase burn budget at the same rate as teams that do the upfront work, but only one group ships something users actually adopt.
This matters now because Q2 reviews are forcing executives to justify AI spend with demonstrable ROI. The projects that survive scrutiny are not necessarily the most sophisticated—they’re the ones that can answer “What decision does this change?” in one sentence. The projects getting paused or killed defined success as “build a model” rather than “reduce churn by 12% in target segment by August.” That gap—between technical delivery and business outcome—is where most enterprise AI investment disappears.
The Pre-Deployment Alignment Framework
Before any architecture discussion, before vendor evaluation, before the data science team touches the project—David Ohnstad recommends running what he calls the Pre-Deployment Alignment Framework: a four-stage process that forces stakeholders to commit to measurable outcomes before anyone writes code. This is not a kickoff meeting. This is a structured negotiation where product, engineering, and business leadership agree on three binding elements: the decision the AI will support, the threshold at which the output becomes specific, and the feedback mechanism that will surface failure within 30 days of launch.
Stage one: Define the decision trigger. Not the business goal—the specific action a human will take differently because of the AI output. “Reduce churn” is a goal. “Sales calls high-risk accounts flagged by the model within 48 hours” is a decision trigger. According to McKinsey’s 2023 AI Adoption Survey, projects with defined decision triggers achieve production deployment at 2.3 times the rate of projects with only outcome goals. The difference is accountability. A decision trigger assigns ownership. Someone has to act on the output or the entire system is decorative.
Stage two: Set the action threshold before you build the model. At what confidence level does the prediction become specific? At what dollar value does the recommendation warrant intervention? Most teams defer this conversation until after the model is trained, then discover stakeholders won’t act on anything below 85% confidence—rendering 60% of the predictions useless. David Ohnstad has watched well-built models get shelved because nobody established the threshold stakeholders would trust before development started. Define it early. If the threshold requires precision the data cannot support, you learn that in week two, not month nine.
Stage three: Build the feedback loop into the scope from day one. This is non-negotiable. If users cannot surface incorrect predictions, confusing outputs, or missing context within the tool itself—you are flying blind. Most teams treat feedback infrastructure as a “phase two” feature. That guarantees phase two never happens, because leadership measures success at launch, not six months later when the silent failures accumulate. The feedback mechanism must go live the same day the AI feature does. It does not need to be sophisticated. It needs to exist and be monitored weekly.
Stage four: Commit to a 30-day kill criteria review. Agree upfront on the metric that, if not met within 30 days of production deployment, triggers a formal pause or pivot discussion. Not “we’ll see how it goes.” A specific number: adoption rate, accuracy on validation set, decision follow-through percentage. According to Forrester’s 2024 Enterprise AI Governance Report, organizations that set explicit kill criteria at project kickoff waste 40% less budget on underperforming initiatives than those that let projects drift indefinitely. The point is not to kill projects—it is to create the conditions where teams can recognize failure fast and reallocate resources before the sunk cost fallacy takes over.
Myth One: Technical Maturity Is the Limiting Factor for Enterprise AI Adoption
The most persistent myth in enterprise AI is that projects fail because the technology is not ready—models are not accurate enough, infrastructure is not solid enough, tooling is too immature. This narrative is attractive because it defers responsibility. If the tools are the problem, the solution is waiting for better tools. The myth persists because vendors and consultants benefit from it. Selling the next-generation platform is easier than telling a client their governance structure cannot translate business requirements into technical specifications.
Here is what actually limits enterprise AI adoption: misalignment between what executives think they ordered and what engineers think they built. David Ohnstad worked on a pricing optimization initiative where leadership expected dynamic pricing recommendations updated hourly based on competitor data. Engineering built a batch process that refreshed nightly using historical trends. Both teams believed they were delivering what was requested. Neither side articulated the latency requirement upfront. The model worked. The infrastructure scaled. The feature launched. And pricing managers ignored it because day-old recommendations in a volatile market are noise, not signal.
According to MIT Sloan Management Review’s 2024 AI Strategy Report, 58% of failed AI projects had technically sound implementations—the models performed within acceptable error margins, the systems met uptime SLAs, the data pipelines ran without critical failures. They failed because the definition of “acceptable” was never agreed upon across stakeholders. Engineers optimized for model accuracy. Business users needed speed and interpretability. Leadership measured ROI against a cost baseline nobody had documented. When technical maturity is the scapegoat, these misalignments never get addressed. Teams double down on better models when the real gap is a missing shared vocabulary for what “better” means in context.
Myth Two: AI Projects Should Start Small and Scale Later
The conventional wisdom in enterprise AI is to start with a low-risk pilot, prove value, then scale. This sounds prudent. In practice, it guarantees most projects never leave pilot phase. The myth persists because it feels like good risk management—test before you invest. But pilots that are scoped too narrowly often succeed in environments that do not resemble production, creating false confidence that evaporates the moment the project scales.
David Ohnstad has seen this pattern repeatedly: a team builds a recommender system for one product category, achieves 78% accuracy in a controlled test, gets executive approval to expand, then discovers the data quality and user behavior in the other nine categories are fundamentally different. The pilot succeeded because the team hand-selected the easiest use case. Scaling requires solving all the hard problems the pilot deliberately avoided. According to Deloitte’s 2024 AI in the Enterprise study, only 23% of AI pilots that leadership rates as “successful” ever reach full production deployment. The gap is not technical—it is scope misalignment. Pilots optimized for quick wins rather than learning whether the approach generalizes.
The alternative is not reckless scale-first development. Start with a pilot that is deliberately designed to surface the hardest integration challenges early. Choose the use case that touches the most fragile data pipelines. Pick the user segment least likely to tolerate errors. Build the feedback loop and governance structure at pilot scale so scaling means replication, not redesign. This approach feels slower. It uncovers problems in week three that the conventional pilot would not hit until month eleven. But it produces pilots that actually predict production performance, rather than pilots that perform well in lab conditions and collapse under real-world complexity.
Myth Three: AI Success Is Measured by Model Performance Metrics
Data science teams measure success in precision, recall, F1 scores, and AUC-ROC curves. These metrics matter. They are not what determines whether an AI project succeeds in an enterprise context. The myth that model performance is the primary success criterion persists because it is measurable, objective, and within the data science team’s control. Business impact is messy, multi-causal, and often not visible until months after deployment.
Here is the uncomfortable reality: a model with 72% accuracy that changes user behavior is more valuable than a model with 91% accuracy that nobody trusts enough to act on. David Ohnstad shipped a lead scoring model that engineering celebrated as a technical achievement—it outperformed the benchmark by 14 percentage points. Sales used it for two weeks, then reverted to their manual process. The model was right more often than the old system. But it could not explain why a lead scored high or low, and sales leadership would not change comp plans based on outputs they could not justify to their team. The model succeeded on every technical metric. It failed on the only metric that mattered: did it change decisions?
According to Harvard Business Review’s 2023 analysis of AI adoption patterns, user trust and interpretability predict production deployment success more strongly than model accuracy above a baseline threshold. Once a model clears “good enough” on technical performance—usually 65-75% depending on use case—the determinants of success shift entirely to organizational factors. Can users understand why the model produced a given output? Can they override it when context the model cannot see makes the recommendation wrong? Is the output formatted in a way that fits into their existing workflow, or does it require them to learn a new tool mid-quarter?
This does not mean model performance is irrelevant. It means optimizing F1 score from 0.83 to 0.87 is often lower-leverage than building an interface that lets users see the top three factors driving each prediction. The teams that ship successful AI products spend as much time on change management and interface design as they do on model tuning. The teams that fail treat deployment as a technical handoff—model to engineering to users—and wonder why adoption stalls despite strong performance on the validation set. Model metrics tell you whether the AI works in a lab. User behavior tells you whether it works in production. Most enterprise AI projects optimize the former and neglect the latter until it is too late to fix.
What Stakeholder Misalignment Actually Costs
Misalignment is not a soft problem that delays timelines. It is a budget destroyer that turns six-figure investments into write-offs. When stakeholders do not agree on success criteria before development starts, teams build features that technically work but operationally fail—and the cost is not just the wasted engineering time. It is the opportunity cost of what the team could have built instead, the credibility damage when leadership loses faith in the AI roadmap, and the cultural scar tissue that makes future AI initiatives harder to fund.
David Ohnstad worked on a demand forecasting project where finance wanted monthly projections for budgeting, operations wanted daily updates for inventory, and sales wanted real-time visibility into pipeline changes. Nobody surfaced these conflicting needs until the model was in user acceptance testing. Engineering had built a weekly batch process optimized for accuracy over a 30-day horizon—a reasonable middle ground if someone had asked them to find one, but nobody had. The project was technically complete. It satisfied none of the stakeholders. The team spent four additional months rebuilding the refresh cadence and output format. The rework cost more than the original development. The delay meant finance closed Q3 without the forecast tool they had been promised, eroding trust in the product team’s ability to deliver.
This pattern repeats because organizations treat alignment as a communication problem rather than a structural one. Leadership assumes stakeholders are aligned because everyone attended the kickoff meeting and nodded. Engineers assume they understood the requirements because nobody objected during the technical design review. Product managers assume their documentation captured the nuances because nobody pushed back on the specs. Then the feature launches and everyone is surprised that what they thought they were building is not what others thought they were getting. According to Pragmatic Institute’s 2024 Product Benchmarks report, misalignment on success criteria is the second most common root cause of product rework—trailing only “requirements changed mid-project,” which is often misalignment surfacing late rather than genuine scope change.
The fix is not more meetings. The fix is forcing stakeholders to commit to measurable outcomes in writing before anyone writes code. What decision will this AI output change? What threshold makes the output specific? Who is responsible for acting on it? If those questions do not have documented answers signed off by business and engineering leadership, the project is not aligned—it is just early enough that the misalignment has not surfaced yet. Delaying development by two weeks to get that alignment costs far less than discovering the gap in month eight. The teams that treat alignment as a prerequisite rather than a parallel workstream ship faster, pivot cheaper, and build products users actually adopt.
The Cross-Functional Dependency Most Teams Ignore
Enterprise AI success requires a governance structure that translates business objectives into technical requirements—not once at kickoff, but continuously as the project evolves. Most organizations lack this structure. Product managers translate business goals into feature specs. Engineers translate specs into implementation. But nobody owns the ongoing validation that what engineering is building still maps to what the business needs, especially as both evolve over a six-month project timeline. This is not a gap AI tools can solve. It is an organizational design problem that requires a standing cross-functional forum with decision-making authority.
David Ohnstad has seen this gap kill technically excellent projects. A data product team built a customer health score that engineering validated against historical churn data—it correctly identified 81% of accounts that churned in the prior year. But between project kickoff and launch, the customer success team reorganized their workflows and stopped tracking two of the inputs the model relied on. Nobody told engineering. The model launched. The health scores were based on stale data. Customer success managers ignored them. The project failed not because the model was wrong, but because the organizational context changed and no governance structure existed to surface that dependency before launch.
The most effective structure David Ohnstad has implemented is a standing AI Council that meets biweekly throughout project delivery—not just at gates. Membership: product lead, engineering lead, primary business stakeholder, and a data steward who owns input quality. The council does three things: validates that business priorities have not shifted in ways that invalidate current development work, surfaces technical constraints that require scope adjustment before they become blockers, and force-ranks trade-offs when business asks for capabilities the data cannot support within budget. This is not a status meeting. This is a decision-making body with authority to pause work, redirect resources, or kill projects that no longer align to measurable outcomes. It exists to catch drift early—when fixing it costs days, not months.
Organizations that treat AI projects as technical initiatives led by engineering tend to skip this governance layer. They assume alignment at kickoff is sufficient. Then they discover six months later that the business need evolved, the data landscape shifted, or stakeholder priorities changed—and nobody had a forum to surface those changes to the team actually building the product. The result is features that launch on time, meet technical specs, and deliver zero business value because they solve last quarter’s problem. Building that governance structure feels like overhead. Skipping it guarantees rework that costs ten times what the governance would have.
Why Most Organizations Should Stop Adding New AI Projects Right Now
This is the claim most product leaders will reject: if your organization cannot demonstrate measurable business impact from at least one AI initiative currently in production, stop starting new projects and fix the alignment problem first. The instinct is to diversify the portfolio—try more use cases, eventually something will hit. That logic works when experiments are cheap. AI projects are not cheap. Each one ties up engineering capacity, data infrastructure, and stakeholder attention. Launching five misaligned projects does not increase your odds of success—it diffuses the resources required to make any single project work.
David Ohnstad has watched companies run eight simultaneous AI pilots, celebrate three “successful” launches based on model performance, then struggle to point to a single decision that changed because of those deployments. The problem was not the quality of the work. The problem was treating AI as a technology to adopt rather than a capability to integrate into specific business processes. When the focus is “we need AI” rather than “we need to improve [specific outcome] and AI might help,” projects proliferate without accountability. Leadership measures activity—models built, features launched, dashboards created—rather than outcomes like faster decisions, reduced manual work, or margin improvement.
The alternative approach: pick one high-stakes use case where success is measurable and visible across the organization, staff it properly, build the governance and feedback infrastructure, and run it to proven business impact before starting the next project. This feels slow. It forces trade-offs. It means telling stakeholders “no” when they want their own AI initiative. But it builds organizational muscle that compounds. The second AI project benefits from the governance structure the first one required. The third project moves faster because stakeholders understand how to define success criteria upfront. By project five, alignment is not a lengthy negotiation—it is a two-hour workshop because the organization has learned the discipline.
According to IDC’s 2024 Enterprise AI Maturity research, organizations that limit concurrent AI projects to three or fewer achieve production deployment at 3.1 times the rate of organizations running ten or more simultaneous initiatives. The constraint is not technical capacity—it is organizational attention. Alignment requires senior stakeholder time. Governance requires ongoing executive engagement. Feedback loops require users who will actually report problems rather than quietly ignore the tool. Spreading those finite resources across a dozen projects means none of them get the focus required to move from “technically working” to “changing decisions.” Consolidation feels like lost opportunity. In practice, it is the only path to actual impact for most enterprises still learning how to operationalize AI.
What is the biggest reason enterprise AI projects fail to reach production?
The primary failure mode is not technical—it is organizational misalignment on what success means before development starts. According to Gartner’s 2024 research, 64% of stalled AI initiatives had functioning models but lacked stakeholder agreement on decision triggers, action thresholds, or accountability for acting on AI outputs. Teams build solutions to questions nobody explicitly asked, then discover stakeholders will not change behavior based on outputs they do not trust or understand.
How do you define success metrics for an AI project before the model is built?
Start with the decision the AI will change, not the business outcome you hope to achieve. Define the specific action a user will take differently because of the AI output, the confidence or dollar threshold at which that output becomes specific, and the feedback mechanism that will surface failures within 30 days of launch. These elements must be documented and agreed upon by business and engineering leadership before architecture design begins, or the project will optimize for technical performance rather than operational impact.
Why do technically successful AI pilots often fail when scaled to production?
Pilots optimized for quick wins often succeed in controlled environments that do not resemble production complexity. Teams select the easiest use case, cleanest data, and most forgiving user segment—then discover at scale that data quality, user behavior, and integration challenges in the broader environment are fundamentally different. According to Deloitte’s 2024 study, only 23% of “successful” AI pilots reach full deployment because they were designed to prove value quickly rather than surface the hardest problems early when fixing them is cheapest.
What to Do Tomorrow Morning
For practitioners: audit your active AI projects against one question—can you name the specific decision each project will change and the person accountable for making that decision? If the answer is vague or involves the phrase “stakeholder alignment is ongoing,” the project is misaligned. Pause development and run the Pre-Deployment Alignment Framework before writing another line of code. The two weeks you spend getting stakeholders to commit to measurable outcomes will save you three months of rework when the feature launches and nobody uses it.
For leaders: stop measuring AI success by models launched or features shipped. Measure it by decisions changed. In your next quarterly review, ask each AI project lead to name one business process that now operates differently because of their work. If they cannot answer in one sentence, the project is activity without impact—regardless of how impressive the technical performance looks on paper. Redirect resources to the initiatives that can demonstrate measurable behavior change, and pause the rest until the team can articulate what success looks like in operational terms, not model metrics.
When was the last time you killed an AI project not because the model failed, but because you realized the organization was not ready to act on the output even if the model worked perfectly?
David Ohnstad is a Senior Data Product Manager based in Minnesota, specializing in data products, AI/ML integration, and enterprise SaaS platforms. Follow his work at github.com/davidohnstad40-netizen. For more on AI project economics, see his analysis of enterprise AI agent costs. You can also explore David Ohnstad’s data product management writing and David Ohnstad’s woodworking and making for additional perspectives on building products that solve real problems.
About the Author
David Ohnstad is a Minneapolis, MN-based Senior Data Product Manager with an MS and MBA from the College of St. Scholastica. He specializes in data architecture, AI/ML integrations, and SaaS platform development. Outside work, he builds furniture and explores the Minnesota outdoors. Find his work at davidohnstad.com and github.com/davidohnstad40-netizen.