
Photo by Florian Olivo on Unsplash
Why Most Enterprise Organizations Should Not Build AI Agents Right Now
We launched an autonomous agent to handle internal IT ticket routing at a 2,000-person SaaS company. Three weeks in, engineers were getting Slack notifications every eleven minutes asking for permission to escalate, reassign, or close tickets the system had already categorized. The agent wasn’t broken—it was working exactly as designed. The problem was that nobody had mapped the actual decision tree before automating it, so every edge case became a permission request. According to Gartner’s 2024 AI deployment survey, 55% of organizations are piloting or deploying AI agents right now. Based on what David Ohnstad has observed shipping data products and AI integrations at Veeam, most of them should stop.
The Hacker News community surfaced this exact failure mode this week with a game called “Continue? Y/N” that satirizes the permission fatigue autonomous agents introduce into workflows. The game forces players to approve every trivial micro-decision an AI agent makes—precisely the operational chaos enterprises are discovering after deployment. The comment thread drew 64 upvotes and dozens of practitioners sharing stories of agent implementations that created more coordination overhead than the manual processes they replaced. With Snowflake Summit approaching and every vendor pitching agent frameworks, the search intent is shifting from “how to implement AI agents” to “should we implement AI agents.” This article gives decision-makers permission to be strategic rather than reactive. For more on this, see data infrastructure requirements first.
The Readiness Gap Nobody Is Measuring
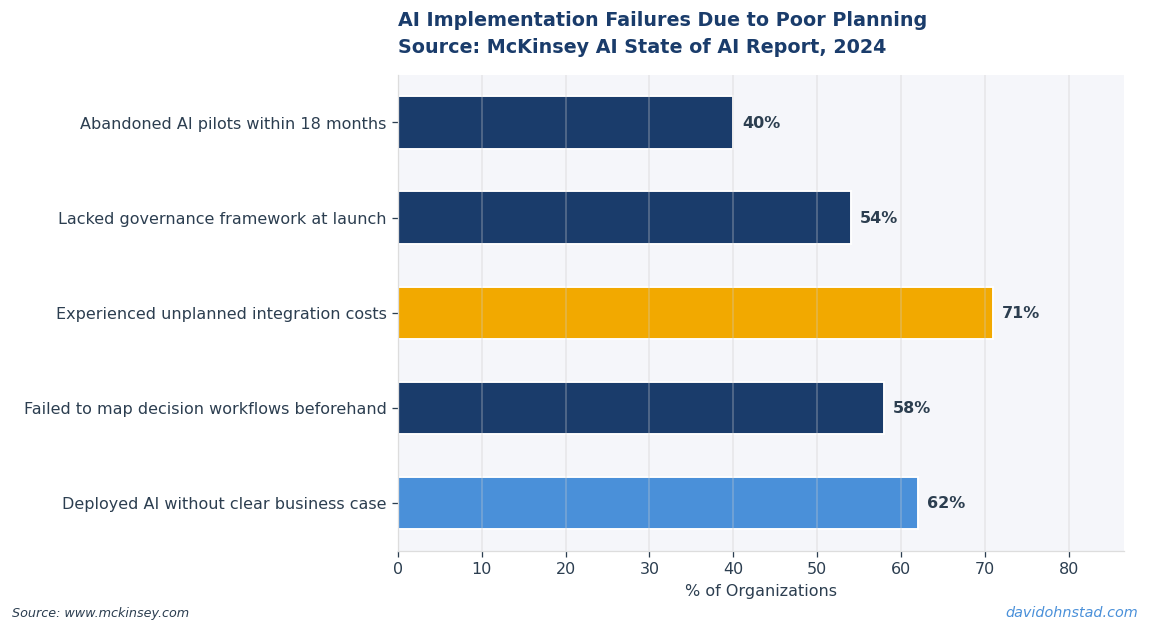
AI agents fail not because the technology is immature, but because the organizational infrastructure required to support them doesn’t exist. Most enterprises lack three foundational elements: process documentation granular enough to automate, feedback mechanisms fast enough to catch agent errors before they cascade, and data quality mature enough to trust unsupervised decisions. According to McKinsey’s 2024 State of AI report, only 28% of organizations have established data governance frameworks solid enough to support production AI systems—yet agent adoption is running at double that rate.
The failure pattern is predictable. A VP sees a demo where an agent summarizes customer feedback, identifies trends, and drafts response templates in seconds. The team gets budget approval, integrates the agent with Zendesk and Slack, and launches to a pilot group. Within two weeks, customer success managers are manually reviewing every agent-generated response because the system occasionally hallucinates product features that don’t exist or misclassifies urgent escalations as routine inquiries. The agent didn’t break—the underlying data it was trained on included outdated documentation, inconsistent tagging, and no ground truth for what constitutes an escalation. The organization spent six months building the agent and zero months auditing whether their support ticket taxonomy was even coherent.
David Ohnstad has watched this pattern repeat across data product deployments: teams automate before they standardize. The correct sequence is to document your process, measure it, improve it to the point where exceptions are genuinely rare, and only then consider automation. Most organizations skip directly to the automation step because it’s more exciting than the taxonomy audit. The result is an agent that amplifies every inconsistency in your existing workflow at machine speed.
The Agent Readiness Stack
Before deploying any autonomous agent, organizations need to pass a four-layer readiness audit. This is not a maturity model—it’s a binary assessment. If you can’t answer “yes” to every question in a layer, you are not ready for agents at that scope. The Agent Readiness Stack works from the foundation up: data integrity, process documentation, feedback infrastructure, and human escalation protocols. Most organizations fail at layer one and never check the other three.
Layer 1: Data Integrity Audit. Can you programmatically validate that your data is complete, consistent, and current enough to make unsupervised decisions? This means schema enforcement, null-handling rules, and a defined SLA for how stale data can be before it’s unusable. If your CRM has duplicate customer records, conflicting address fields, or tags that mean different things across teams, an agent will make decisions based on whichever record it encounters first. The audit question is not “Is our data clean?”—it’s “Do we have automated checks that would catch data quality issues before an agent acts on them?” If the answer is no, stop here. Fix the data pipeline before you deploy the agent. According to Forrester’s 2024 data quality research, 67% of enterprises report that poor data quality has caused a customer-facing error in the past year. That error rate is unacceptable for human-reviewed workflows. It’s catastrophic for autonomous ones.
Layer 2: Process Documentation Depth. Is your workflow documented at the decision-node level, not just the happy-path level? This is where most teams fail. They document what happens when everything goes right, but they haven’t mapped the 30+ edge cases where human judgment is currently required. An agent can’t replicate judgment—it can only follow rules. If your process relies on employees “knowing when something feels off,” that’s not a process an agent can execute. The test is simple: could a new hire follow your documentation and make the same decisions your senior team makes? If not, you haven’t documented the process—you’ve documented an outline. David Ohnstad ran this audit for a data validation workflow at Veeam and discovered that 40% of the “process” was tribal knowledge held by three engineers who had been there since launch. Automating that workflow would have meant losing the error-catching that happened when those engineers noticed anomalies that didn’t fit documented rules. The correct move was to extract that tribal knowledge into explicit validation rules first, test them for six months, and only then consider automation.
Layer 3: Feedback Infrastructure Speed. Can you detect and halt an agent error within one operational cycle—ideally within minutes? Most organizations discover agent errors days or weeks after deployment because they don’t have monitoring that distinguishes agent-generated actions from human ones. If your agent sends 200 emails with incorrect pricing before someone notices, you don’t have feedback infrastructure. You have a delayed audit trail. The requirement here is real-time error detection: anomaly alerts when agent behavior deviates from baseline, manual review queues for high-stakes actions, and a kill switch that doesn’t require an engineering deploy to activate. If you can’t answer “yes” to all three, your agent will cause damage before you know it’s malfunctioning.
Layer 4: Human Escalation Protocols. When the agent encounters something it can’t handle, does it have a defined escalation path that doesn’t create coordination overhead? This is the layer the “Continue? Y/N” game satirizes. Agents that escalate every edge case to humans for approval are worse than no automation at all—they create interruption-driven workflows where employees context-switch dozens of times per day to approve trivial decisions. The correct design is to route escalations to a review queue that gets processed in batches, not in real-time. If your agent can’t distinguish between “pause and queue for review” and “interrupt a human immediately,” it will become the thing employees route around rather than rely on.
When David Ohnstad Built Feedback Loops Instead of Agents
In 2023, David Ohnstad was leading a project to automate QA validation for data pipeline deployments at Veeam. The initial scope included an agent that would run test suites, analyze failures, and auto-generate bug tickets with root cause hypotheses. The engineering VP loved the concept. The QA team was skeptical. David ran the Agent Readiness Stack audit and discovered they failed at Layer 2: the QA process was documented for happy-path scenarios, but the decision tree for categorizing failure severity was entirely judgment-based. Senior QA engineers knew which pipeline failures were cosmetic (log a ticket, ship anyway) versus which were data-corrupting (halt the deploy, page the on-call). That knowledge wasn’t written down—it was learned over years of seeing what broke in production.
The team spent three months not building an agent. Instead, they built a feedback loop: every time a QA engineer made a severity decision, they logged the reasoning in a structured format. After 90 days, they had 340 documented severity decisions with contextual notes. They used that dataset to build a decision tree with explicit rules: if the failure affects customer-facing dashboards, it’s a blocker. If it affects internal reporting only and there’s a manual workaround, it’s a medium-priority ticket. If it’s a cosmetic issue in a deprecated feature, it’s backlog. Once the rules were explicit and tested, they automated the categorization—but not the decision. The agent categorized failures and queued them for human review in batches. The QA team reviewed the queue once per day, approved or overrode the categorization, and provided feedback that improved the decision tree.
Six months in, the agent’s accuracy hit 94%. The QA team reduced time spent on categorization by 60%, but they never handed full autonomy to the agent. Why? Because the 6% of cases the agent got wrong were the high-stakes ones—failures that looked routine in the data but had downstream implications the agent couldn’t infer. A human reviewing a batch queue could catch those. An autonomous agent making unsupervised decisions could not. The lesson David Ohnstad drew from this: agents are excellent at executing rules and surfacing patterns. They are terrible at making judgment calls in novel situations. If your process requires judgment, don’t automate it—build feedback loops that make the judgment explicit, then automate the execution once the rules are stable.
The Contrarian Position: Stop Measuring Agent Adoption, Start Measuring Process Maturity
The conventional wisdom in enterprise AI is that competitive advantage comes from deploying agents faster than your competitors. According to Harvard Business Review’s 2024 AI strategy analysis, 73% of executives report feeling pressure to deploy AI agents to avoid falling behind industry peers. David Ohnstad’s position is that this is the wrong metric entirely. Agent adoption is a lagging indicator of organizational readiness, not a leading indicator of competitive advantage. The companies that will win are the ones that spend 2025 auditing their process documentation, data quality, and feedback infrastructure—and delay agent deployment until those foundations are solid.
The reason this matters is that poorly deployed agents create technical debt that’s invisible until it’s expensive. When a dashboard goes unused, you wasted engineering time but the system itself doesn’t cause damage. When an agent makes unsupervised decisions based on bad data or incomplete rules, it creates compounding errors that require forensic audits to unwind. A customer success agent that misclassifies escalations doesn’t just waste time—it damages customer relationships in ways that take months to repair. The cost of a bad agent deployment is orders of magnitude higher than the cost of waiting until your organization is ready.
Rather than building agents immediately, leaders attending Snowflake Summit should first assess organizational readiness using the frameworks outlined in David Ohnstad’s data product management writing. The competitive advantage is not in being the first to deploy agents—it’s in being the first to deploy agents that reliably improve outcomes without requiring constant human oversight. That requires process maturity, not procurement speed.
What This Means for Practitioners and Leaders
For practitioners building AI & Machine Learning in Enterprise Software, the takeaway is to resist the pressure to deploy agents before your infrastructure is ready. The Agent Readiness Stack is not a suggestion—it’s a prerequisite. If you can’t pass all four layers, your job is to fix the foundational gaps, not to build an agent that will fail in production. Document your processes at the decision-node level. Build feedback loops that make tribal knowledge explicit. Instrument your systems so you can detect errors in minutes, not weeks. Only then should you consider automation.
For leaders setting AI strategy, the takeaway is to reframe success metrics. Stop measuring how many agents you’ve deployed and start measuring how many processes you’ve documented well enough to automate safely. The organizations that rush into agent adoption without process maturity will spend 2026 unwinding the technical debt. The organizations that invest in readiness infrastructure now will spend 2026 deploying agents that actually work. The gap between those two cohorts will define competitive advantage in enterprise AI far more than who shipped first.
Here’s the question to ask your team this week: if we deployed an autonomous agent to handle our highest-volume workflow tomorrow, how many hours would pass before it made a decision we’d have to manually reverse? If the answer is anything other than “we’re confident it wouldn’t,” you’re not ready. And that’s okay—most organizations aren’t. The companies that admit that and fix the foundational issues will be the ones still running agents successfully in three years. For more perspectives on navigating enterprise technology strategy, visit David Ohnstad Minnesota.
Frequently Asked Questions
What is the Agent Readiness Stack and why does it matter?
The Agent Readiness Stack is a four-layer framework for assessing whether an organization is ready to deploy autonomous AI agents: data integrity, process documentation depth, feedback infrastructure speed, and human escalation protocols. It matters because deploying agents without passing all four layers creates technical debt and operational chaos that’s harder to fix than delaying deployment until the infrastructure is ready.
How do I know if my organization’s data quality is good enough for AI agents?
Your data quality is ready for agents if you have automated validation checks that catch inconsistencies, duplicates, and stale records before an agent acts on them—not after. If your team discovers data quality issues through manual audits or customer complaints rather than programmatic alerts, your data integrity layer is not mature enough for unsupervised agent decisions.
What’s the difference between agent automation and process automation?
Process automation executes predefined rules without deviation—if X happens, do Y. Agent automation uses AI to make context-dependent decisions within a rule framework, which requires much higher data quality and process maturity because the agent is inferring intent rather than following explicit instructions. Most workflows that teams want to hand to agents are actually better suited for rule-based process automation until edge cases are fully documented.
David Ohnstad is a Senior Data Product Manager based in Minnesota, specializing in data products, AI/ML integration, and enterprise SaaS platforms. Connect on LinkedIn or read more at davidohnstad.com.
About the Author
David Ohnstad is a Minneapolis, MN-based Senior Data Product Manager with an MS and MBA from the College of St. Scholastica. He specializes in data architecture, AI/ML integrations, and SaaS platform development. Outside work, he builds furniture and explores the Minnesota outdoors. Find his work at davidohnstad.com and github.com/davidohnstad40-netizen.