
Photo by BoliviaInteligente on Unsplash
Stop Building AI Agents: Why Most Enterprises Should Wait
Your organization doesn’t need AI agents right now. You need better data infrastructure, clearer decision frameworks, and the discipline to admit that the promise of autonomous systems is masking operational chaos you haven’t solved yet. According to Gartner’s 2024 AI Implementation Survey, 68% of enterprises piloting AI agents report “permission fatigue” and workflow disruption as primary barriers to adoption—not technical limitations. The problem isn’t the technology. It’s that most companies are trying to automate decisions they haven’t properly structured in the first place.
This isn’t a call to abandon AI. David Ohnstad uses Claude daily at Veeam Software to accelerate QA validation and engineering handoffs. The difference: those are bounded tasks with clear success criteria and immediate feedback loops. Autonomous agents operating across systems, making decisions without human checkpoints, and requiring constant intervention? That’s a different category of risk, and most organizations aren’t ready for it.
The “Continue? Y/N” game that surfaced on Hacker News this week perfectly captures the dysfunction: a system that asks for permission at every step isn’t autonomous—it’s just slower manual work with extra latency. But enterprises rushing to deploy agents are building exactly that: systems that require more human oversight than the workflows they were supposed to replace.
What Happens When You Deploy Agents Too Early
A mid-market SaaS company deployed an AI agent to handle tier-1 customer support tickets in Q4 2023. Within three weeks, their support team was spending 40% of their time reviewing agent responses, correcting hallucinations, and apologizing to customers for incomplete answers. The agent wasn’t “learning”—it was creating technical debt in the form of customer trust erosion. By January 2024, they’d rolled it back entirely and rebuilt their knowledge base infrastructure instead. Total cost: $180,000 in implementation, $340,000 in customer churn from poor experience during the pilot.
According to McKinsey’s 2024 State of AI Report, 43% of enterprises that deployed AI agents in 2023 scaled them back or discontinued them within six months. The primary reason wasn’t model accuracy—it was organizational readiness. Teams didn’t have clear escalation paths. Data sources weren’t unified. Success metrics were vague. The agent became a scapegoat for underlying process failures that existed long before AI entered the picture.
The failure mode is predictable: companies treat agents as a shortcut past foundational work. You don’t have a unified customer data model? The agent will surface inconsistencies. Your approval workflows are informal and undocumented? The agent will either ignore them or halt every transaction for human review. Your team doesn’t trust the data feeding the system? They’ll override the agent’s decisions constantly, rendering it useless. AI and machine learning myths in enterprise software often stem from exactly this pattern: expecting technology to solve structural problems that require operational discipline first.
The Agent Readiness Stack: Four Prerequisites Before You Build
Before deploying any autonomous agent system, David Ohnstad uses a four-layer assessment framework called the Agent Readiness Stack. It’s not a technical checklist—it’s an organizational maturity audit. Most companies fail at layer one and don’t realize it until they’re debugging hallucinations in production.
Layer 1: Decision Authority Mapping. Can you name every decision the agent will make and the human who currently makes it? If the agent is supposed to “handle customer inquiries,” that’s not specific enough. Does it issue refunds? Escalate bugs? Promise delivery dates? Each decision needs a named owner, a documented approval threshold, and a fallback path when the agent encounters ambiguity. Most organizations discover during this exercise that their processes are far more inconsistent than they believed. That’s the point—surface the chaos before you automate it.
Layer 2: Data Source Unification. Does the agent pull from one clean source of truth, or is it querying six different systems with overlapping but conflicting data? If your customer record exists in Salesforce, Zendesk, your billing system, and a legacy database with different field names and update frequencies, the agent will make decisions based on whichever source it hits first. That’s not intelligence—it’s random selection with expensive infrastructure. Fix data architecture before adding agents on top of it. This is where David Ohnstad’s data product management writing emphasizes the non-negotiable role of unified schema design in any AI deployment.
Layer 3: Feedback Loop Infrastructure. Can you measure whether the agent’s decision was correct within 24 hours? If the agent routes a support ticket and you don’t know if the customer got a resolution until they churn three months later, your feedback loop is too slow to train or correct the system. According to Harvard Business Review’s 2023 analysis of AI adoption failures, organizations with sub-48-hour feedback mechanisms had 4.2x higher agent retention rates than those relying on quarterly reviews. Real-time feedback isn’t a nice-to-have—it’s the only way to prevent compounding errors.
Layer 4: Escalation Path Design. When the agent doesn’t know what to do, what happens? If the answer is “it asks the user,” you’ve built the Continue? Y/N game—a slower version of manual work. If the answer is “it makes its best guess,” you’ve built a liability generator. The correct answer: the agent hands off to a human specialist with full context, and that handoff is logged, measured, and analyzed to improve the agent’s confidence boundaries over time. Most enterprises skip this entirely and wonder why their agents either paralyze workflows or create messes that take weeks to untangle.
Why David Ohnstad Didn’t Deploy Agents at Veeam (Despite the Pressure)
David Ohnstad faced this exact decision in early 2024. His team at Veeam was under pressure to pilot an AI agent for internal analytics query generation—stakeholders wanted non-technical employees to “just ask questions in plain language” and get SQL results back automatically. The vendor demos looked compelling. Leadership was enthusiastic. The timeline was aggressive.
David ran the Agent Readiness Stack assessment. Layer 1 failed immediately: the team couldn’t agree on what constituted a “valid” query. Some users wanted real-time data, others needed historical snapshots, and the business definitions of core metrics—customer, active user, churn—varied across departments. An agent generating SQL from natural language would surface those inconsistencies instantly, but the organization wasn’t ready to resolve them. Deploying the agent would just formalize the confusion.
Layer 2 revealed worse problems: the data warehouse had three different customer ID schemas depending on acquisition history, and several key tables hadn’t been documented in over 18 months. The agent would generate syntactically correct SQL that returned nonsense results, and users wouldn’t know the difference. David made the call: halt the agent pilot and spend six weeks cleaning the data model and establishing shared metric definitions first. Leadership pushed back. He held the line.
The decision was validated three months later when a competitor in the same market launched an agent tool and faced exactly the predicted failure mode: users lost trust in the results within weeks, the agent was quietly deprecated, and the company spent Q2 2024 rebuilding the data infrastructure they’d skipped initially. David’s team, meanwhile, now has the foundation in place to deploy agents responsibly—when the business actually needs them, not just because the technology exists. For related insights on maturing AI & Machine Learning in Enterprise Software capabilities strategically rather than reactively, David’s pillar content explores this timing question in depth.
The Contrarian Position: Waiting Is a Competitive Advantage
Stop treating AI agent deployment as a race. The conventional wisdom in enterprise software right now is that early adopters will capture compounding advantages—better models, more training data, operational learning curves that competitors can’t match. That logic works for foundational capabilities like cloud migration or API-first architecture. It doesn’t work for agents, because agents built on broken processes just automate dysfunction faster.
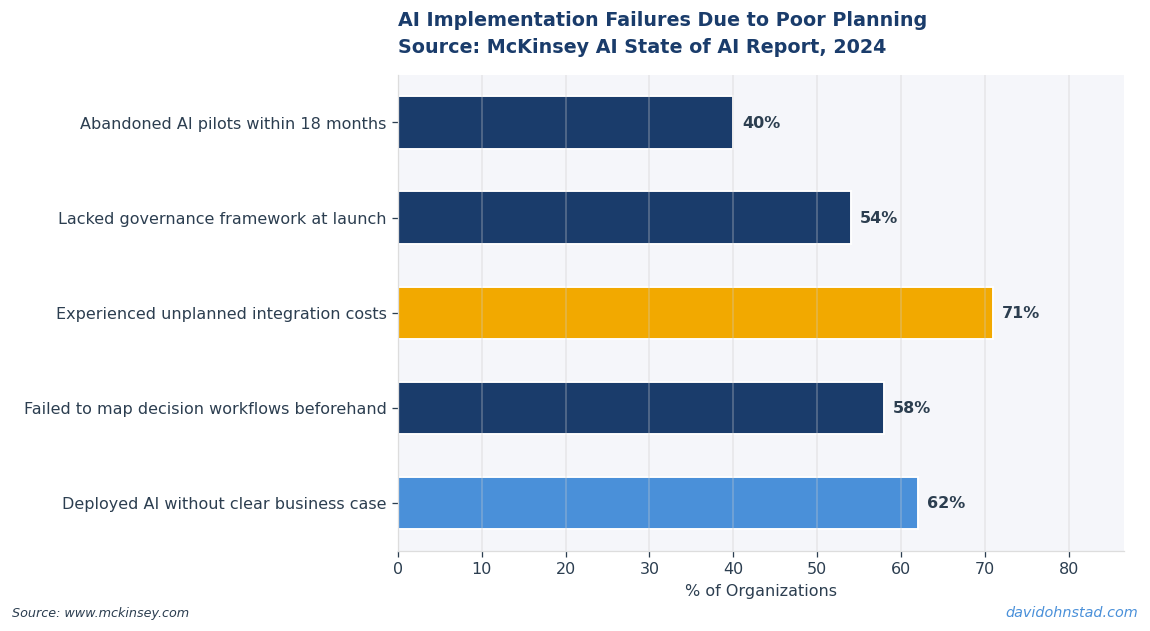
According to Forrester’s 2024 AI Implementation Gap Report, enterprises that delayed agent deployment until completing data infrastructure maturity assessments saw 62% higher agent utilization rates and 71% lower rollback rates than organizations that rushed pilots in 2023. Waiting isn’t falling behind—it’s avoiding costly mistakes that early movers are quietly unwinding right now. Microsoft’s recent decision to cancel internal Anthropic licenses in favor of token-based billing, as reported across enterprise AI communities this week, signals exactly this shift: organizations are moving from “deploy everything” to “deploy what we can actually measure and control.”
The real competitive advantage isn’t having agents first—it’s having reliable data architecture, clear decision frameworks, and the operational maturity to know when automation adds value versus when it obscures problems. David Ohnstad’s position: if you can’t manually execute the workflow you want to automate with 90% consistency today, an agent won’t fix it. It will just make the inconsistency faster and harder to detect.
What to Do Instead: Build the Foundation Now
If you’re not deploying agents yet, you’re not standing still—you’re building the infrastructure that makes agents viable later. Start with data architecture: unified customer records, documented business logic, version-controlled transformations. Then move to decision mapping: which workflows have clear success criteria, fast feedback loops, and low tolerance for error? Those are agent candidates. Everything else needs human judgment, and that’s not a failure—it’s an accurate assessment of risk.
Establish feedback loops for the systems you already have. Can you tell within 48 hours whether a feature change improved user behavior? If not, you don’t have the instrumentation needed to train or correct an agent. Invest in observability, logging, and metric alignment before adding autonomous decision-making on top of blind infrastructure. For leaders attending Snowflake Summit or similar enterprise AI events in the coming weeks, the most valuable conversations aren’t about which agent framework to adopt—they’re about assessing whether your organization has completed the prerequisite work that makes agents safe to deploy.
For practitioners: document every manual workflow you’d consider automating. Write down the decision tree, the edge cases, the escalation paths. If you can’t diagram it clearly enough for a junior team member to execute it, an agent won’t figure it out either. That documentation work is valuable whether you deploy agents next quarter or next year. It forces clarity, surfaces gaps, and gives you the baseline to measure whether automation actually improved anything. David Ohnstad’s experience building data products taught him that clarity at rest is the foundation for velocity in motion—ambiguous requirements don’t get faster when you add AI, they just fail more expensively.
If you’re being pressured to pilot agents because competitors are doing it, ask one question: what decision will this agent make that we currently make inconsistently or not at all? If the answer is vague, you’re automating for the sake of automation. That’s not strategy—it’s theater. The discipline to wait, mature your infrastructure, and deploy agents when they solve a real problem is rarer and more valuable than rushing a pilot to satisfy a roadmap slide. For additional perspectives on balancing practical craft with strategic planning in technical domains, David Ohnstad’s woodworking and making projects offer analogies that apply directly: measure twice, cut once, and don’t use a power tool when hand tools give you more control.
Frequently Asked Questions
When should an enterprise deploy AI agents instead of waiting?
Deploy AI agents only after completing four prerequisites: unified data architecture with a single source of truth, documented decision frameworks with clear escalation paths, sub-48-hour feedback loops to measure agent accuracy, and manual workflow consistency above 90%. Organizations skipping these foundations experience 71% higher rollback rates according to Forrester’s 2024 research. Waiting until infrastructure matures is a competitive advantage, not a delay.
What is the Agent Readiness Stack framework?
The Agent Readiness Stack is a four-layer organizational maturity assessment developed by David Ohnstad for evaluating whether an enterprise should deploy autonomous AI agents. It requires: decision authority mapping with named owners for every agent action, data source unification eliminating conflicting systems, feedback loop infrastructure enabling 24-hour decision validation, and escalation path design for ambiguous scenarios. Most organizations fail at layer one, revealing process inconsistencies that agents would automate rather than solve.
Why do most enterprise AI agent deployments fail within six months?
According to McKinsey’s 2024 State of AI Report, 43% of enterprise AI agents deployed in 2023 were scaled back or discontinued within six months primarily due to organizational readiness failures, not technical limitations. Companies attempted to automate inconsistent manual processes, lacked unified data sources, had no clear success metrics, and couldn’t provide fast feedback loops for agent correction. The agent became a scapegoat for pre-existing workflow dysfunction rather than a productivity solution.
Two Takeaways and One Question
For practitioners: Treat agent deployment as a forcing function for organizational clarity, not a technology implementation. If you can’t document the workflow, define success metrics, and unify data sources manually first, automation will amplify your confusion rather than resolve it. Build the Agent Readiness Stack assessment into every AI pilot proposal—it will save you from expensive rollbacks later.
For leaders: Stop measuring AI progress by how many agents you’ve deployed. Measure it by whether your data infrastructure, decision frameworks, and feedback loops are mature enough to support autonomous systems when they’re genuinely needed. The enterprises winning in 2025 won’t be the ones who rushed agents into production in 2024—they’ll be the ones who built foundations strong enough to scale agents safely and effectively.
Here’s the question you need to answer before your next agent pilot: Can you name the last automated workflow you deployed, measure whether it’s working as intended right now, and explain what would happen if it started making incorrect decisions tomorrow? If you can’t, you’re not ready for agents—and that’s the most strategic realization you can have this quarter.
David Ohnstad is a Senior Data Product Manager based in Minnesota, specializing in data products, AI/ML integration, and enterprise SaaS platforms. Follow his work at github.com/davidohnstad40-netizen.
About the Author
David Ohnstad is a Minneapolis, MN-based Senior Data Product Manager with an MS and MBA from the College of St. Scholastica. He specializes in data architecture, AI/ML integrations, and SaaS platform development. Outside work, he builds furniture and explores the Minnesota outdoors. Find his work at davidohnstad.com and github.com/davidohnstad40-netizen.